5 Best Free Data Mining Software For Windows
Here is a list of Best Free Data Mining Software For Windows. These software are used to perform various data mining operations in order to extract useful information from datasets. The supported file formats to import datasets include CSV, ARFF, DATA, TXT, XLS, etc. files. Most of these provide a set of sample dataset files which you can import for analysis.
In terms of operations, these let you perform data manipulation, classification, association, regression, clustering, modeling, and data visualization. Each of these provide several algorithm to support respective tasks. For example, for Clustering, you can use K-Means, Kohonen-SOM, LVQ, Neighborhood Graph, etc. algorithms. For Association, you can apply A priori, A priori MR, A priori PT, Assoc Outlier, Frequent Itemsets, etc. rules. For Data Visualization, Scaterrplots, Box Plot, Distribution, Heat Map, etc. methods can be used, and so on. One of these is a text data mining software which lets you analyze text data using various methods.
The results can be viewed on the interface and can also be saved as reports in different formats. All in all, these are good software that you can use for data mining tasks for free.
My Favorite Data Mining Software For Windows:
I quite liked Weka as it provides all sufficient tools to perform primary data mining tasks. It is also not that difficult to use. Orange is also good for professionals as it provides a unique approach to perform data mining operations which is by using widgets.
You may also like some best free Free Spreadsheet Software, Data Visualization Tools, and Database Schema Designer for Windows.
Weka
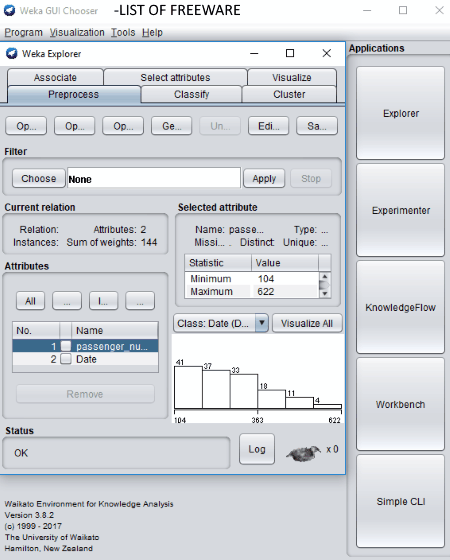
Weka is a featured free and open source data mining software Windows, Mac, and Linux. It contains all essential tools required in data mining tasks. Its main interface is divided into different applications which let you perform various tasks including data preparation, classification, regression, clustering, association rules mining, and visualization. You get various techniques and algorithms to perform these tasks. Lets have a look at its main features:
Data Mining with Weka:
Here are the applications which divide data mining tasks into easily manageable sections:
- Explorer: This application is used for data pre processing, data classification, data clustering, association, and data visualization. You can open data files in several formats including arff, data, CSV, JSON, Matlab ASCII files, dat, etc. You can also open a set of instances from a URL or database. It also provides a tool called DataGenerator to generate artificial data. Various classifier rules can be chosen from, including DecisionTable, OneR, PART, ZeroR, etc. EM, Canopy, Cobweb, FarthestFirst, FilteredClusterer, HierarchicalClusterer, SimpleKMeans, etc. clustering algorithms are available to select from. Association rules including Apriori, FilteredAssociator, and FPGrowth can be used. It provides a tab called Select attributes which basically evaluates relevance of attributes. For this, you can select an attribute evaluator (CfsSubsetEval, ClassifierAttributeEval, OneRAttributeEval, InfoGainAttributeEval, etc.) and a method (GreedyStepwise, BestFirst, Ranker). The respective output is displayed in respective tabs for each of aforementioned tasks.
- KnowledgeFlow: It performs same data mining processes as mentioned in Explorer, but with more tools. It handles data either incrementally or in batches. Some of its features include: chain filtering together, showing models produced by classifiers for each fold in a cross validation, and visualizing performance of incremental classifiers during processing. Here, you also get numerous data visualization methods including Text Viewer, Image Viewer, Attribute Summarizer, Strip Chart, Model Performance Chart, Boundary Plotter, Scatter Plot Matrix, Graph Viewer, and Cost Benefit Analysis.
- Experimenter: Using this application, you can create, run, and analyse experiments of different types including cross validation, train/test percentage split, random split result, learning rate result, etc. You can define a dataset, specify iteration controls, and choose an algorithm to perform experiment.
A Workbench application is also provided which is used to perform same tasks as mentioned in above applications.
All in all, it is a nice free data mining software. It is also not that tough to operate but if you still have difficulty, you can check this video tutorial in order to view detailed explanations of tasks.
Orange
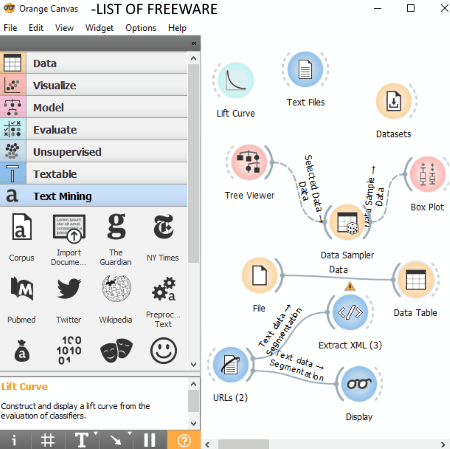
Orange is another free and open source data mining software for Windows. It provides several tools for data manipulations, data modeling, data visualization, and data analysis. It divides these tasks in different categories to easily perform them.
Features of Orange:
- Data: It provides tools for data manipulation. The main tools provided in here are Paint Data, Data Sampler, Rank and Filter Data, Merge Datasets, Transpose Data Table, Randomize, Continuize, Feature Constructor, Purge Domain, Discretize, Outliers, etc.
- Visualize: Here, you can perform data visualization. You can visualize data using several methods including Tree Viewer, Box Plot, Distribution, Scatter Plot, Sieve Diagram, FreeViz projection, Linear projection, Radviz, Heat Map, Venn Diagram, SIlhoutte Plot, Pythagorean Tree Visualization, Nomogram, etc.
- Model: You get various models for the data modeling and prediction task. These include CN2 Rule Induction, Constant, Linear Regression, Logistic Regression, Naive Bayes, AdaBoost, Neural Network, Stochastic Gradient Descent, etc.
- Evaluate: From here, you can evaluate classification or regression performance using various estimation techniques like Test & Score, Predictions, Confusion Matrix, ROC Analysis, Lift Curve, and Calibration Plot.
- Text Mining: It contains text mining and analysis tools like preprocessing text, Twitter text mining, Wikipedia text mining, sentiment analysis, bag of words, etc.
- Unsupervised: This module is used for unsupervised learning which provides tools to read distances from files, view distance matrix, hierarchical clustering, correspondence analysis, multidimensional scaling, manifold learning, etc.
How to use Orange:
In order to work with this software, you need to use several tools as widgets. To create widgets, you can drag tools from left panel and drop them to the canvas. For example, to import a dataset, drag and drop the File tool to the canvas. You can connect one widget to another to perform respective task on the dataset and to view respective results. Here is a quick video tutorial to get started with this software.
This is another good data mining software which is provided free of charge.
Tanagra
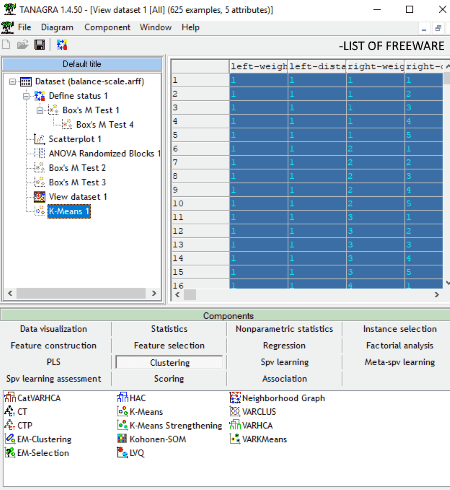
Tanagra is another free data mining software for Windows. It lets you perform different data mining operations. These operations include Association, Regression, Clustering, Spv Learning, Meta-spv Learning, Statistics, Nonparametric Statistics, Factorial Analysis, PLS, Spv Learning Assesment, and Data Visualization. All of these data mining tasks can be performed using various related algorithm and techniques. First, it lets you import datasets in TXT, ARFF, and XLS and create a data mining diagram with it. You can then use any of aforementioned data mining operation to extract useful information. The data mining diagram can be copied as an image or saved as text data mining diagram (tdm) or binary data mining diagram (bdm). An HTML result report can also be saved locally.
Let’s see what are the algorithms you get to perform a data mining task in it:
- Association: A priori, A priori MR, A priori PT, Assoc Outlier, Frequent Itemsets, Spv Assoc Rule, Spv Assoc Tree.
- Regression: Backward Elimination Reg, C-RT Regression Tree, DfBetas, Epsilon SVR, Forward Entry Regression, Multiple Linear Regression, Nu SVR, Outlier Detection, Regression Assessment, Regression Tree, Simultaneous Regression.
- Clustering: CT, CTP, EM-Clustering, EM-Selection, HAC, K-Means, Kohonen-SOM, LVQ, Neighborhood Graph, VARCLUS, VARHCA, VARKMeans.
- Data Visualization: Correlation Scatterplot, Export dataset, Scatterplot, Scatterplot with Labels, View Dataset, View multiple scatterplots.
- Spv Learning: Binary Logistic Regression, C4.5, C-PLS, C-RT, CS-CRT, CS-MC4, C-SVC, Decision List, ID3, K-NN, Linear Discriminant Analysis, Log-Reg TRIRLS, Multilayer Perception, Multinomial Logistic Regression, Naive Bayes, Naive Bayes Continuous, PLS-DA, PLS-LDA, Prototype-NN, Radial Basis Function, Rnd Tree, Rule Induction, SVM.
- Meta-spv Learning: Arcing, Bagging, Boosting, Cost Sensitive Bagging, Const Sensitive Learning, Multicost, Supervised Learning.
- Spv Learning Assesment: Bias-Variance Decomposition, Bootstrap, Cross-Validation, Hosmer Lemeshow Test, leave-One-Out, Logistic Regression Residuals, Test, Train Test.
- Statistics: ANOVA Randomized Blocks, Bartlett’s Test, Box’s M test, brown-Forsythe’s Test, Fisher;s Test, Group Characterization, Group exploration, Hotelling’s T2, Hotelling’s T2 Heteroscedastic, Levene’s Test, Linear Correlation, More Univariate Cont Stat, Normality Test, one-way ANOVA, One-way MANOVA, Paired T-Test, Paired V-Test, Partial Correlation, semi-partial Correlation, T-Test, T-Test Unequal Variance, Univariate Continuous Stat, Univariate Discrete Stat, Univariate Outlier Detection, Welch ANOVA.
- Nonparametric Statistics: Ansari-Bradley Scale Test, Categorical r, Cochran’s Q-test, Contingency Chi-Square, Friedman’s ANOVA by Ranks, FYTH 1-way ANOVA, Goodman Krushkal Gamma, Goodman Krushkal Lambda, Goodman Krushkal Tau, Kendall Tau-b, Kendall Tau-c, Kendall’s tau, Kendall’s Concordance W, Klotz Scale Test, Kruskal-Wallis 1-way ANOVA, K-S 2-sample test, Mann-Whitney Comparison, Median Test, Mood Runs Test, Mood Scale Test, Partial Theil U, Sign Test, Sommers d, Spearman’s rho, Theil U, Van der Waerden 1-way ANOVA, Wald-Wolfowitz Runs Test, Wilcoxon Signed Ranks Test.
- Factorial Analysis: Canonical Discriminant Analysis, Correspondence Analysis, Factor Rotation, Multiple Correspondence Analysis, NIPALS, Principal Component Analysis.
- PLS: PLS Conf. Interval, PLS Factorial, PLS Regression, PLS Selection, PLSR.
- Scoring: List Curve, Posterior Prob, Precision-Roll Curve, Reliability Diagram, Roc Curve, Scoring.
- Feature Construction: Binary Binning, Trend, Residual Scores, MDLPC, Cont to Disc, etc.
It provides quite a lot of tools to perform data mining tasks. In order to understand it more closely, you can check this video tutorial.
NeoNeuro Data Mining
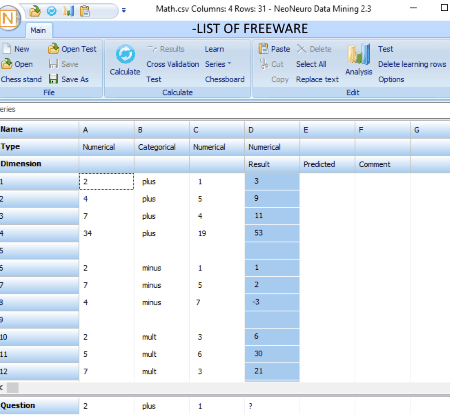
NeoNeuro Data Mining is the next data mining software in this list. It basically allows machine learning for various common and multidimensional clustering tasks.
In it, you can open datasets in TXT, CSV, XLS, etc. formats. You can also create a new dataset for performing related tasks. It provides a Calculation section which contains options like Cross Validation, Series Calculation, etc. It also provides an Analysis tool for data analysis which estimates the most important parameters and visually represents the influence of each parametric value. It also creates Excel formula which you can use in your business processes or science researches. Check this video tutorial in case of any difficulty understanding it.
Note: It is free non-commercial use only.
khcoder
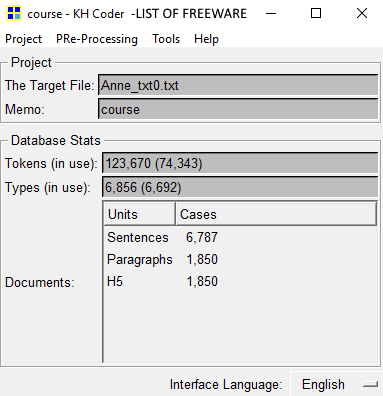
khcoder is basically a text data mining software and is used for quantitative content analysis. It provides a lot of tools for analysis which include Word Association, KWIC Concordance, Descriptive Stats, Correspondence Analysis, Multidimensional Scaling, Hierarchical Cluster Analysis, Cooccurrence Network, Self Organizing Map, and Frequency List. It provides a Naive Bayes Classifier tool too.
It is basically used for text analysis. It processes text files and creates number of sentences, paragraph, tokens, memo, frequency list, co-occurrence frequency, etc. results. You can further add plugins to this software to add more features to this software. The final results can be saved in its native format.








About Us

We are the team behind some of the most popular tech blogs, like: I LoveFree Software and Windows 8 Freeware.
More About UsArchives
- May 2024
- April 2024
- March 2024
- February 2024
- January 2024
- December 2023
- November 2023
- October 2023
- September 2023
- August 2023
- July 2023
- June 2023
- May 2023
- April 2023
- March 2023
- February 2023
- January 2023
- December 2022
- November 2022
- October 2022
- September 2022
- August 2022
- July 2022
- June 2022
- May 2022
- April 2022
- March 2022
- February 2022
- January 2022
- December 2021
- November 2021
- October 2021
- September 2021
- August 2021
- July 2021
- June 2021
- May 2021
- April 2021
- March 2021
- February 2021
- January 2021
- December 2020
- November 2020
- October 2020
- September 2020
- August 2020
- July 2020
- June 2020
- May 2020
- April 2020
- March 2020
- February 2020
- January 2020
- December 2019
- November 2019
- October 2019
- September 2019
- August 2019
- July 2019
- June 2019
- May 2019
- April 2019
- March 2019
- February 2019
- January 2019
- December 2018
- November 2018
- October 2018
- September 2018
- August 2018
- July 2018
- June 2018
- May 2018
- April 2018
- March 2018
- February 2018
- January 2018
- December 2017
- November 2017
- October 2017
- September 2017
- August 2017
- July 2017
- June 2017
- May 2017
- April 2017
- March 2017
- February 2017
- January 2017
- December 2016
- November 2016
- October 2016
- September 2016
- August 2016
- July 2016
- June 2016
- May 2016
- April 2016
- March 2016
- February 2016
- January 2016
- December 2015
- November 2015
- October 2015
- September 2015
- August 2015
- July 2015
- June 2015
- May 2015
- April 2015
- March 2015
- February 2015
- January 2015
- December 2014
- November 2014
- October 2014
- September 2014
- August 2014
- July 2014
- June 2014
- May 2014
- April 2014
- March 2014
